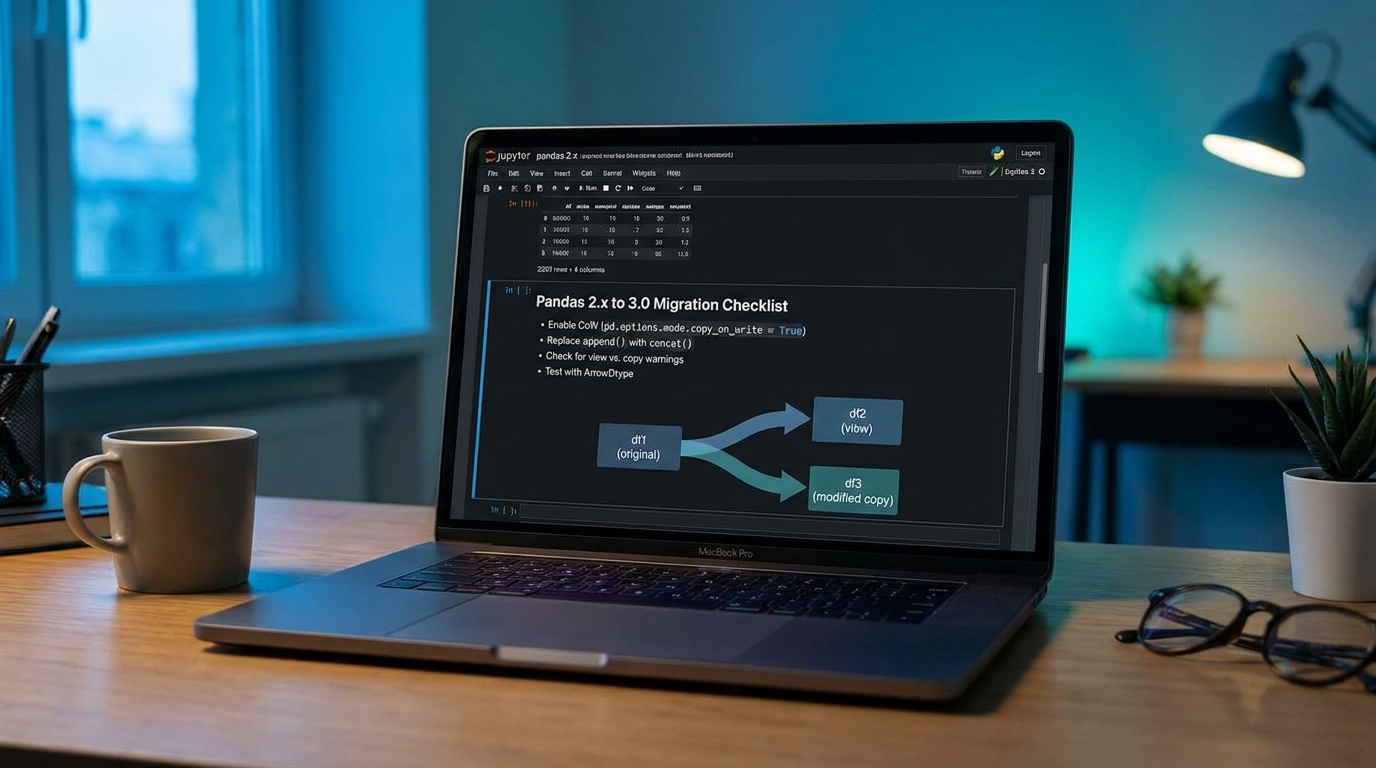
Practical pandas copy-on-write migration guide for data teams: fix chained assignment, adapt string dtype changes, and upgrade to pandas 3.0 with confidence.
Category: Data Science
-

The Model Was Fine, Our Time Travel Was Wrong: A 2026 Playbook for Point-in-Time Joins and Leakage-Proof Features
Point-in-time joins done right: stop data leakage in machine learning with dbt snapshots, feature freshness SLOs, and reproducible training data pipelines.
-

The Dashboard That Changed After Lunch: An Iceberg Snapshot Audit Workflow with Spark, DuckDB, and dbt
Practical Iceberg snapshot audit workflow using Spark, DuckDB, and dbt to trace metric drift, validate backfills, and debug data changes with confidence.
-

The Late Event That Rewrote Friday: A Data Science Playbook for Watermarks, Incremental dbt Models, and Safe MERGE Backfills
Late-arriving events reconciliation made practical with event-time watermarks, dbt incremental models, and safe MERGE backfills for trustworthy dashboards.
-

From Spreadsheet Chaos to a Laptop Lakehouse: DuckDB + Iceberg + dbt for Reproducible Analytics
Build a DuckDB Iceberg lakehouse with dbt incremental models for local-first, reproducible analytics, safer schema changes, and fewer metric surprises.
-

Data Science in 2026: Build a Real-Time Fraud Detection Feature Pipeline with Flink, Feast, and XGBoost
Fraud detection systems fail less often because of model quality and more often because of data quality, feature freshness, and serving inconsistency. A model can score 0.95 AUC in notebooks and still miss real attacks in production if online features…
-

Data Science in 2026: Build a Fast Analytics Pipeline with Polars, DuckDB, and Python
Most data teams in 2026 are under pressure to ship insights faster without adding heavy infrastructure. A practical pattern is to combine Polars for blazing-fast dataframe transforms and DuckDB for local analytical SQL. In this guide, you will build a…
-

Pandas 3.0 in 2026: 10 Powerful New Features That Will Transform Your Data Workflows
Pandas 3.0, released in early 2026, is the biggest overhaul of Python's most popular data manipulation library in over a decade. With Apache Arrow as the default backend, built-in GPU acceleration, and a redesigned API, it's faster, more memory-efficient, and…
-

Polars vs Pandas in 2026: Why Your Data Pipelines Need a Speed Upgrade
If you're still using Pandas for every data task in 2026, you're leaving massive performance gains on the table. Polars — the Rust-powered DataFrame library for Python — has matured into a production-ready powerhouse that processes data 10-50x faster than…
-

Polars vs Pandas in 2026: Why Python Developers Are Switching to Polars for Data Analysis
If you're still using Pandas for every data task in 2026, you're leaving serious performance on the table. Polars, the Rust-powered DataFrame library for Python, has matured into a production-ready alternative that's 10-100x faster for common operations. In this guide,…
-
Pandas 3.0: Essential Data Manipulation Techniques Every Data Scientist Needs
Pandas 3.0, released in late 2025, brings significant performance improvements with Apache Arrow backend by default. Here are the essential techniques for efficient data manipulation.Arrow-Backed DataFramesimport pandas as pd # Pandas 3.0 uses Arrow by default df = pd.read_csv("large_dataset.csv") #…