At 1:17 AM, our on-call channel looked calm, but one workload had quietly lost access to S3. Nothing dramatic in Kubernetes events, no obvious node issue, no bad deploy. The real problem was IAM drift. We had the same microservice in three EKS clusters, and our IRSA trust policies had become a brittle copy-paste museum. One cluster got the trust update, two did not. The app was “healthy,” but writes were dead.
That incident pushed us to a migration I had avoided for months: moving selected workloads from IRSA to EKS Pod Identity, without breaking the pieces that still needed IRSA.
This guide is the runbook I wish I had that night. It is opinionated, practical, and focused on one outcome: fewer identity footguns in real production clusters.
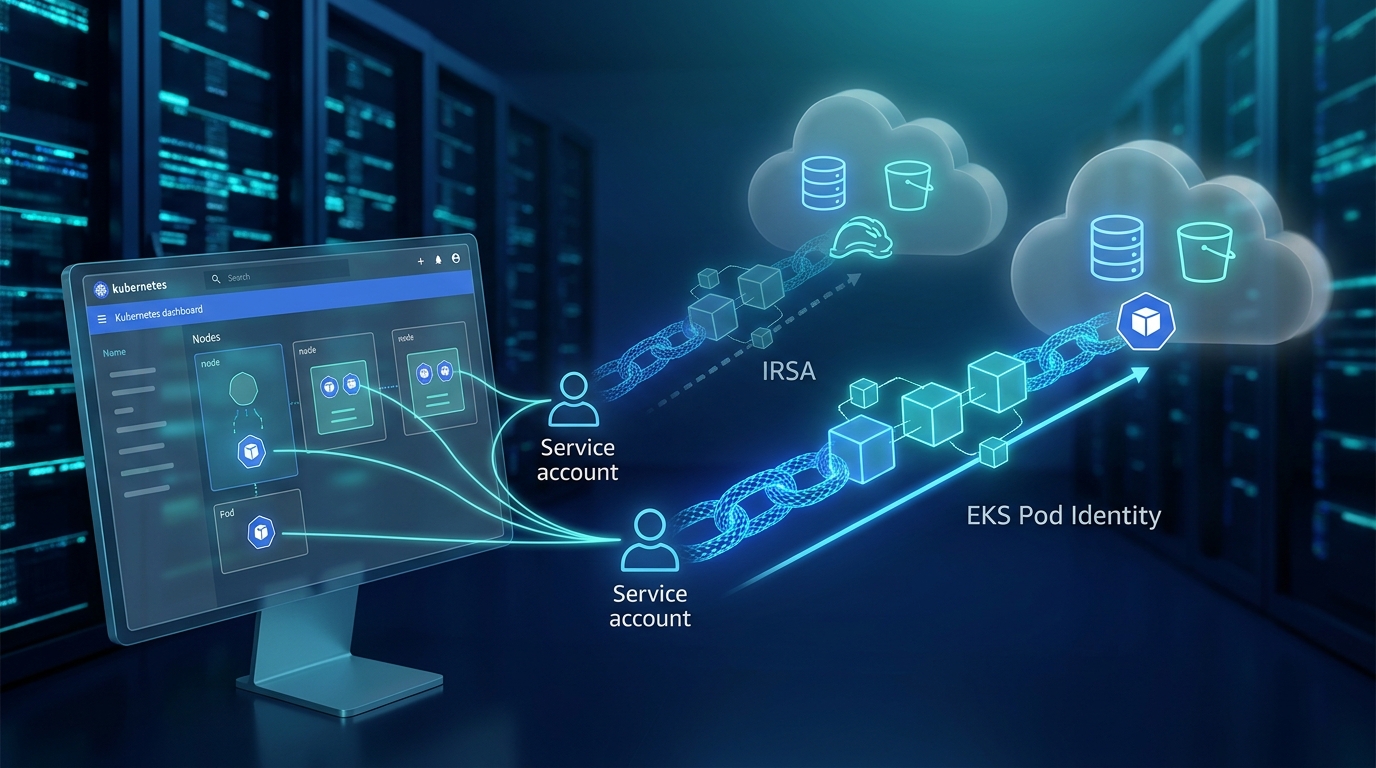
The core shift: from OIDC-heavy wiring to EKS-managed associations
Both IRSA and EKS Pod Identity let Kubernetes workloads assume IAM roles through service accounts. The difference is operational shape:
- IRSA depends on per-cluster OIDC provider wiring and trust-policy conditions tied to OIDC subjects.
- EKS Pod Identity uses the
pods.eks.amazonaws.comservice principal and EKS-managed associations between role, cluster namespace, and service account.
In teams with many clusters, this matters a lot. IRSA works well, but trust policies can sprawl quickly. Pod Identity reduces that trust-policy churn and avoids per-workload STS AssumeRoleWithWebIdentity patterns in application code paths.
Where Pod Identity is better, and where IRSA still wins
I am not treating this as “new replaces old.” The tradeoff is situational:
- Pod Identity is usually better when you run standard EKS on EC2 Linux nodes and want simpler role reuse across clusters.
- IRSA is still required in environments where Pod Identity is not available, including EKS Anywhere and some non-EC2 Linux pod scenarios documented by AWS.
- Pod Identity adds session tags automatically (cluster, namespace, service account), which is great for ABAC style controls.
- Pod Identity associations are eventually consistent, so do not create or mutate them in hot request paths.
If you are designing broader reliability controls, this pairs nicely with earlier posts on idempotent AWS scheduling patterns and workflow integrity checks in CI.
A migration pattern that avoids downtime
Step 1, pick one low-blast-radius service account
Start with a workload that has clear IAM boundaries, for example read/write to a single bucket prefix. Avoid shared “god” service accounts in phase one.
Step 2, create a Pod Identity compatible trust policy
For Pod Identity, your IAM role trust policy needs the EKS Pods service principal. Keep it minimal first.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "pods.eks.amazonaws.com"
},
"Action": [
"sts:AssumeRole",
"sts:TagSession"
]
}
]
}
Then keep permissions in the role policy as tight as possible. If you want one reusable role across namespaces or clusters, use principal tags from Pod Identity sessions (for example ${aws:PrincipalTag/kubernetes-namespace}) in IAM conditions.
Step 3, create the EKS association and roll one deployment
Use AWS CLI to bind role + service account + namespace at the cluster level. Then restart only the target deployment.
# 1) Create association
aws eks create-pod-identity-association \
--cluster-name prod-cluster-a \
--namespace payments \
--service-account reconciler \
--role-arn arn:aws:iam::123456789012:role/eks-payments-reconciler
# 2) Restart workload to pick up fresh credentials path
kubectl -n payments rollout restart deploy/reconciler
# 3) Verify from pod
kubectl -n payments exec deploy/reconciler -- aws sts get-caller-identity
During this step, keep IRSA annotation removal for later in the same maintenance window, after validation. That gives you a clean rollback path.
Step 4, verify before cleanup
- CloudTrail shows expected role assumptions.
- App can read/write only intended resources.
- No STS throttling surprises under load test.
- Pod restarts still get valid credentials.
When stable, remove legacy IRSA annotation from the service account and redeploy once more to ensure no hidden dependency remains.
Production gotchas most teams hit once
The following three issues are the ones I now check first:
- Old SDK versions
Pod Identity relies on SDK support in the default credential chain. If a workload pins outdated SDKs, it may ignore Pod Identity credentials and fail unpredictably. - Proxy bypass gaps
If pods use outbound proxies, make sureNO_PROXYincludes Pod Identity local endpoints (AWS documents link-local addresses). Miss this once, and credentials fail only in certain environments. - Assuming “eventual consistency” means instant
Right after creating or editing associations, some pods may not immediately observe the change. Build a short retry window into deployment runbooks.
If your platform team is simultaneously hardening policy boundaries, these patterns connect well with our earlier write-up on stateful access-control drift, plus the Kubernetes guardrails from admission control policy design.
What to measure in the first 7 days after migration
The migration is not done when the role assumption works once. I treat week one as a controlled observation window.
- Credential error rate per workload: compare pre-migration and post-migration auth failures, not just aggregate cluster health.
- STS call profile: if you moved hot workloads, watch for reduced direct STS pressure and fewer burst throttling patterns.
- Role reuse safety: if multiple service accounts now share one IAM role, validate that condition keys and principal tags are actually constraining access.
- Rollback readiness: keep a tested rollback note for each migrated workload, including previous service account setup and deployment hash.
This sounds boring, but this is where most identity migrations fail. Teams validate happy path, skip post-cutover telemetry, and discover edge-case denials only during unrelated deploys days later.
Troubleshooting: quick diagnosis matrix
Symptom: AccessDenied after migration
- Confirm pod is running with the intended service account.
- Run
aws sts get-caller-identityinside the pod and compare role ARN. - Check role policy conditions that use principal tags; a wrong tag key can silently deny access.
Symptom: credentials work in one cluster but not another
- Validate association exists in each cluster, same namespace, same service account spelling.
- Verify Pod Identity Agent is installed and healthy on worker nodes.
- Check whether the failing environment is on an unsupported compute type for Pod Identity.
Symptom: intermittent auth failures during deploy windows
- Account for eventual consistency after association updates.
- Use rollout sequencing, not all-cluster restarts at once.
- Temporarily keep old IRSA config until post-rollout verification is complete.
FAQ
1) Should I migrate every IRSA workload to Pod Identity immediately?
No. Migrate by risk slice, not ideology. Start with high-noise, low-risk services where trust-policy sprawl already hurts. Keep IRSA where your environment requires it.
2) Does Pod Identity remove the need for least-privilege IAM design?
Not at all. It simplifies delivery and association, but over-broad role policies are still over-broad role policies. Pod Identity reduces wiring complexity, not security responsibility.
3) Can I reuse one IAM role safely across multiple workloads?
Yes, but only with strict condition keys and principal-tag-aware policies. If you skip conditions, role reuse becomes shared blast radius in disguise.
Actionable takeaways
- Adopt a mixed model: Pod Identity by default on supported EKS workloads, IRSA where platform constraints require it.
- Migrate one service account at a time, and keep rollback simple until post-deploy validation passes.
- Audit SDK versions before migration, otherwise credential-chain behavior can invalidate your rollout assumptions.
- Use Pod Identity session tags to make role reuse safer, not broader.
- Document association creation and verification as a standard change template for platform teams.
Leave a Reply